





视频大模型画饼哪家强?Gen-3演示效果绝杀Sora!
自从OpenAI公布了Sora,视频生成领域正式按下了行业加速键,许多国内外企业纷纷发力,不仅研究发布专门用于视频生成的垂直大模型,还将手里的技术封装成一个个人人能用的AIGC产品。
随着新玩家数量的剧增,这场视频生成领域的战争愈演愈烈,其中受到冲击最大的自然是老牌同类竞品模型,比如Pika、SDV、谷歌、Meta,还有在昨天发布了第三代视频生成模型Gen-3 Alpha的Runway。
Gen-3很香,但你暂时用不了
Runway深夜发布的各种演示视频展示出了电影级的画面细节,直接震惊了全体网友。Gen-3与之前的旗舰视频模型Gen-2相比,在模型生产速度和保真度方面有了重大提升,同时对生成视频的结构、风格和运动提供了细粒度的控制。
Runway表示,Gen-3 Alpha具有高保真视频、精细动作控制、逼真人物生成、多模态输入、专业创作工具、增强安全、高质量训练等特点。在这次模型的训练过程中,汇集了研究者、工程师和艺术家的集体智慧和努力。正是这种跨学科的协作精神,使得Gen-3 Alpha模型能够理解和表达多种风格和电影概念。
官方展示视频时长为10秒,人物生成中的人物面部细节和情感营造方面比较细腻,场景、风景生成中的元素、光影没有太大的违和感。友情提示,以下展示内容因为要转换为GIF,所以画质均有不同程度压缩,想看原视频的朋友可以去Runway官网复习下。
女子乘坐车辆穿过明暗交替的街道,外部光源照射在面部的变化十分自然,车外穿梭的车辆也没有出现断层等违和场景。

图源:Runway
男子似乎在类似电影院的昏暗地方观看影视作品,双眼微红、眼球转动、眨眼以及嘴部轻微抽动等细节还原度非常高。

图源:Runway
一间破旧的屋子,地面被魔法转化成植物门,植物在阳光下随风飘扬,随着镜头向前推进展现更多细节。

图源:Runway
一团火焰漂浮半空,在街道游荡,火焰细节明显比其他元素要难掌握,边缘有些飘忽,加上虚化背景上的人们也有滑行的动作,这个视频算是暴露了Gen-3的缺点。
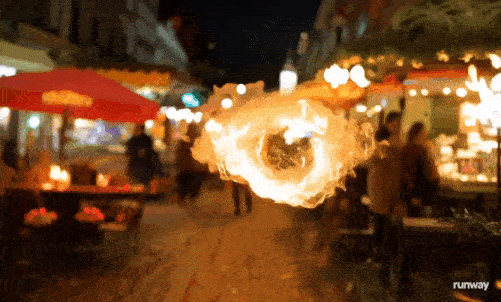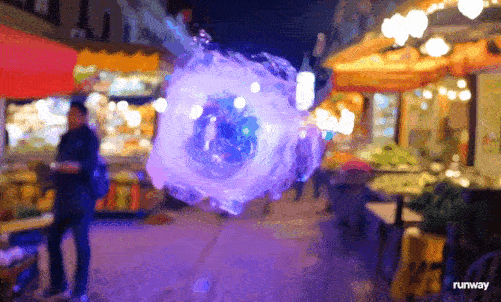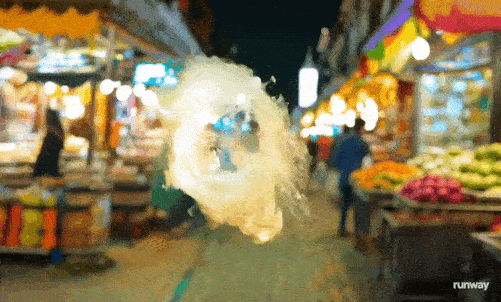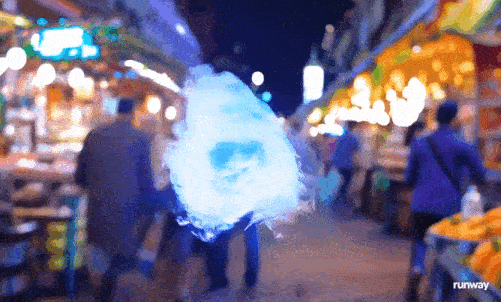
图源:Runway
接下来是本人最喜欢的一个视频,电影级别的镜头推进仿佛一下就将人们带进了宏大的异世界,如果小雷没有记错的话,侏罗纪公园、金刚等电影经常用这种镜头。镜头背景太广,因此也不奢望能展示多少细节,至少大体看上去没发现什么瑕疵。

图源:Runway
尽管大家看到基于Gen-3生成的短视频都很激动,但还是得稍微冷静冷静,因为Runway暂时不提供Gen-3的使用。预计还要再过几天,它才会向Runway订阅用户开放,包括企业客户和Runway创意合作伙伴计划中的创作者。
也就是说,普通用户短时间内还是无法使用Gen-3,只能用Gen-2解解馋。说起来,小雷还没体验过Runway的视频生成模型,Gen-2就Gen-2吧,通过对比看看Gen-3的升级幅度是不是真有那么大。
体验完Gen-2,我才明白Gen-3升级力度有多大
进入生成界面,小雷立马感受到了Runway与视频生成产品的不同。用户不仅可以采用“傻瓜式”一键输入关键词生成,还能对主体运动强度、相机控制、运动轨迹、等细节进行微调,至于风格、纵横比、清晰度也是标配了。
图源:Runway
但也有要强烈吐槽的地方,那就是视频生成需要排队,用户要么等待,要么只能选择升级订阅套餐,也就是付费。小雷体验过这么多国内外视频生成大模型应用,这是我第一次遇到这种情况。

图源:Runway
这是小雷生成的第一个视频,生成4s的视频花了大概2分钟,原本想生成一个CGI风格的荒原视频,但这效果直接给我来了一记重击。看这个视频时直接让我想起了CS画风,草丛“蠕动”异常难看,视频中所有房子的屋顶均有不同程度的频闪,给人一种置身异次元空间的感觉。

图源:Runway
第二个视频的关键词是“脸上有雀斑的红发年轻人注视窗外”,最终呈现结果大家看看就好,能感觉Gen-2在努力营造光线在人物面部渐变的层次感,然而效果并不自然,人物脸上的雀斑没识别到,脖子被胡须侵袭成了蛇皮状,人物想眨眼又眨不了的样子一言难尽。

图源:Runway
生成了两个视频后,小雷实在体验不下去了,感觉Gen-2的水平还停留在2023年视频生成模型刚出来的阶段,与现在市面上其他视频生成模型完全不在一个档次上。无论是人物还是风景,基于Gen-2生成视频给人的最大感受就是不真实,也难怪Runway对Gen-3的描述是“巨大提升”。
体验完Gen-2这个上代旗舰,小雷才真正感受到Gen-3的强大。不与其他视频生成模型比较,Runway在超越自己这件事上就已经赢了。
小雷注意到不少网友可能是拿到了内测资格,在网上分享自己的试用作品,视频效果与官方展示视频大体相同,因此大家也不用担心未来Gen-3公开版本“缩水”的情况。不过在Gen-3真正上线前,大家还是得耐心等待。
视频生成模型竞争,进入加速阶段
Runway成立于2018年,是国外一家在线视频剪辑制作网站。团队起初积极将AI技术运用到视频处理中,开发了根据文本生成图像、根据图像生成风格化变体、图像延展外绘、根据文本生成 3D 贴图纹理、视频局部无损放大等功能,主要用于降低视频创作的门槛,帮助人们轻松制作出内容强大且富有创意的视频内容,这也为其接下来推出的文生视频生成技术打下基础。
Runway本次发布的第三代视频生成模型Gen-3 Alpha,在官方公布视频中的效果可以称得上是惊艳。虽然不知道大规模运用后的效果如何,但就目前来说,个人认为已经超越了Sora。而且Sora自从今年2月发布以来,至今仍无法公开使用,给其他视频生成模型留下了充足的追赶时间。
事实上,就在Sora发布的那个月,国内文生视频领域便已开始升温。清华大学公布的文生视频专利、中国首部文生视频AI动画片《千秋诗颂》播出、国内首个音视频多媒体大模型万兴“天幕”正式公测等国内文生视频成果,如雨后春笋般涌现。
近期,快手直接上线了可灵视频生成大模型及可灵AI应用,号称第一个普通人也能用的文生视频应用。小雷受邀进行了内测体验,在视频质量上,虽然依旧无法彻底解决复杂交互情况下的物理规律难题,但作为面向普通用户的免费大模型应用,小雷认为没有太多可挑剔的地方,毕竟这个瑕疵是整个行业都暂时无法解决的。
Sora暂时“搁浅”,其他文生视频的不断涌现,让整个行业陷入前所未有的竞争格局,视频生成领域正处于变革加速期。
据市场调研机构Gartner研究预测,到2030年,预计人工智能将主导数字内容的创造,占到总量的90%。根据预测,全球人工智能生成内容(AIGC)的市场规模将从2022年的108亿美元显著增长,到2032年将达到1181亿美元。
理想的市场预期大概率会催生更激烈的行业竞争,文生视频下阶段的竞争重点或许将围绕落地应用和商业化展开。越来越多企业把应用和模型同步去做优化、迭代,单一大模型的参数堆叠和技术提升已不再是大模型行业竞争的首要因素。
假如Sora一鸽再鸽,迟迟不推出落地应用,前期积累的行业影响力恐怕只会为他人做嫁衣。
来源:雷科技
原文标题 : 视频大模型画饼哪家强?Gen-3演示效果绝杀Sora!
 分享
分享















发表评论
登录
手机
验证码
手机/邮箱/用户名
密码
立即登录即可访问所有OFweek服务
还不是会员?免费注册
忘记密码其他方式
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论